




Multiple sources confirm that on June 12, 2025 Google suffered a major global outage affecting its cloud and consumer services.
Outages were first noticed around midday UTC and continued for several hours. For example, TechCrunch reported “large swaths of the internet” went down that afternoon, noting “a Google Cloud outage is at the root of these service disruptions”. Google itself later said the outage began ~10:49 am PDT and by 6:18 pm PDT residual issues had largely cleared up. The incident lasted roughly 3 hours (start 10:49am, end 1:49pm PDT)
In contrast to rumors that the outage was some external attack, Google’s internal postmortem explicitly pins the cause on a software bug. Google’s status report explains that a recent code change in the Service Control component (part of its API management/control plane) lacked proper error handling. On June 12 a policy update containing blank fields triggered this untested code path, and “the null pointer caused the binary to crash” in every region. In other words, an unhandled null-pointer exception in Google’s quota-checking service control binary caused a crash loop across Google’s API infrastructure. (Google notes that a “kill switch” was pressed once the bug was found and traffic was rerouted, and smaller regions recovered quickly; larger regions like us-central1 needed up to ~2 h 40 m more due to backlogs.)
For example, Google’s incident report states:
On May 29, 2025, a new feature was added…without appropriate error handling… Without [this], the null pointer caused the binary to crash”. It goes on: a policy change at 10:45 am PDT inserted blank fields, which “hit the null pointer causing the binaries to go into a crash loop” globally. Thus, the null pointer exception rumor is confirmed by Google’s own report: the outage was indeed triggered by an unhandled null-pointer in its service code
Services Affected and Duration
The outage was extensive. Down-detector aggregators and Google’s dashboards show dozens of products impacted:
- Google Workspace apps: Gmail, Google Calendar, Google Drive, Docs, Meet, Chat, Cloud Search, Google Tasks, Google Voice, etc. (Google’s official list of impacted Workspace products includes Gmail, Calendar, Drive, Chat, Docs, Meet, Cloud Search, Tasks, etc.)
- Google Cloud Platform services: The Cloud Console, APIs, and backend services (Compute, Storage, Dataproc, Pub/Sub, etc.) all showed errors. Google’s status page notes “multiple Google Cloud products” saw elevated 503 errors. (Tom’s Guide captured the Cloud status page reporting “outage” for dozens of services.)
- Consumer Google services: Down-detector reports peaked for Google Search (google.com), Maps, and even YouTube and Nest. For example, Tom’s Guide noted that outage reports spiked for “Google Search, Gmail and YouTube” among others. Similarly, 9to5Google logged outages across Google.com, Gmail, Nest/Home, Cloud, Meet, Drive, Maps, YouTube and other services at the peak of the incident.
- Third-party apps: Many popular internet services went dark because they rely on Google Cloud. Reports and news outlets confirmed outages at Spotify, Discord, Snapchat, and others on June 12. Cloudflare also saw some services (its KV store) fail and later attributed that to Google’s outage.
In sum, Google’s own consoles and customer reports show a broad swath of its ecosystem was down. The duration of the main outage was about three hours: Google’s incident timeline lists “Incident Start: 12 June 2025 10:49” and “Incident End: 12 June 2025 13:49 (Duration: 3 hours)”. (Most regions and services recovered by ~12:48 pm PDT, but the largest region took longer.) Within about two hours of the fix, most affected services were back up, though some residual error backlogs lingered briefly
For example, Google’s status dashboard (cloud.google.com/service-health) briefly showed dozens of services with warning triangles. The screenshot below, captured during the event, shows the Cloud Service Health page with many products marked as “affected” across regions
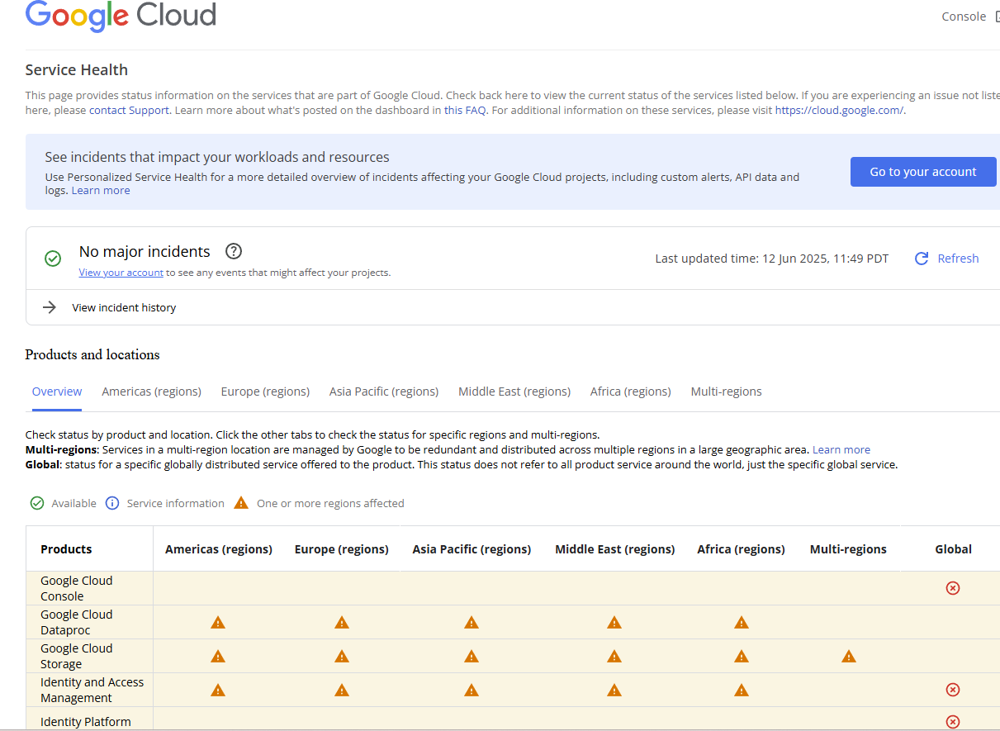
As news reports noted, users worldwide saw their Google Docs go blank, Nest devices stop working, and API calls fail during those hours
Cause: Null Pointer in Service Control
According to Google’s postmortem, the root cause was an invalid quota policy update triggering a null-pointer bug. In essence: a single unhandled exception in Google’s Service Control binary crashed the system. Google explains that on May 29 a new quota-check feature was rolled out without a protective feature flag. This code path only executes if certain fields exist. On June 12 an automated policy update (replicated globally via Spanner) contained blank fields, which led Service Control into the new code branch. Because the code lacked error-handling, it immediately hit a null pointer and “the binaries went into a crash loop”. The crash loop then cascaded through the API infrastructure worldwide.
This scenario matches early industry analysis. For example, The Register summarized Google’s report: Google admitted it “did not have appropriate error handling… Without the appropriate error handling, the null pointer caused the binary to crash”. In other words, the outage was self-inflicted by a software bug. A Reddit summary (based on Google’s report) even headlined it “root cause… null pointer exception” — exactly what Google confirms. No evidence was found of malicious activity; it was purely a code/feature bug.
Google’s engineers identified the issue within minutes and applied a “red-button” kill switch. Within 10–25 minutes the faulty policy check was disabled, allowing most regions to recover. However, in large regions the restart of Service Control created a load spike, which took longer (nearly 3 hours total in us-central1) to fully resolve. In short, a single missing-null-pointer check in Google’s API management code briefly took down much of Google’s cloud and workspace infrastructure.
Official Statements and Postmortem
Google has publicly acknowledged and analyzed the outage. On June 12 Google’s official status pages and dashboards were updated repeatedly; Google’s only formal statement that day (cited by Reuters) simply said the issue with Chat, Meet, Gmail, Calendar, Drive, etc. “has been resolved for all affected users,” and promised a later analysis. Hours later Google’s engineering status page posted a mini incident report (timestamped 11:34 pm PDT June 12) summarizing the timeline above and noting “From our initial analysis, the issue occurred due to an invalid automated quota update… causing external API requests to be rejected”. (Google said it bypassed the bad quota check to recover, leaving behind some backlog which cleared within the next hour.)
Google also apologized publicly. BleepingComputer reports Google said on its status update, “We are deeply sorry for the impact this service disruption/outage caused… we will do better,” and promised a full incident report after investigation. The Register notes Google promised to improve its communications, saying it will “improve our external communications… so our customers get the information they need asap” in future outages. In other words, Google has confirmed the root cause (the null-pointer quota bug), outlined the fix sequence, and pledged better safeguards (feature flags, error checks, etc.) going forward.
In summary, the June 12, 2025 outage was real and widely documented. Google’s official postmortem confirms it was caused by a null-pointer error in its Service Control code. The disruption lasted roughly three hours and impacted core Google Workspace (Gmail, Docs, Meet, etc.) and Cloud services, as well as consumer services like Search and YouTube. Google has publicly acknowledged the incident, apologized, and published initial findings on its Service Health dashboard. A more detailed postmortem is expected from Google once its internal review is complete.